CVPR is a top international conference in the field of computer vision, pattern recognition and artificial intelligence, which will be held in New Orleans in 2022. We will organize the summary of each article as follows (ranking first or later), welcome to read!
DINE:Domain Adaptation from Single and Multiple Black-box Predictors
Authors: Jian Liang, Dapeng Hu, Jiashi Feng, Ran He
Code: https://github.com/tim-learn/DINE
This paper studies a practical and interesting setting for UDA, where only black-box source models (i.e., only network predictions are available) are provided during adaptation in the target domain. To solve this problem, we propose a new two-step knowledge adaptation framework called DIstill and fine-tuNE (DINE). Taking into consideration the target data structure, DINE first distills the knowledge from the source predictor to a customized target model, then fine-tunes the distilled model to further fit the target domain. Besides, neural networks are not required to be identical across domains in DINE, even allowing effective adaptation on a low-resource device. Empirical results on three UDA scenarios (i.e., single-source, multi-source, and partial-set) confirm that DINE achieves highly competitive performance compared to state-of-the-art data-dependent approaches.

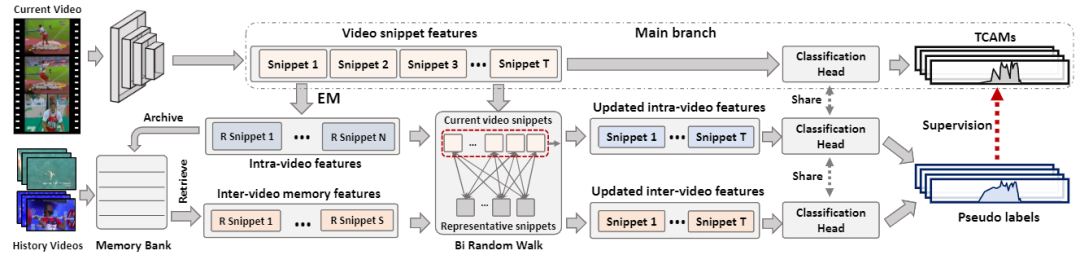
Weakly Supervised Temporal Action Localization via Representative Snippet Knowledge Propagation
Authors: Linjiang Huang, Liang Wang, Hongsheng Li
Code: https://github.com/LeonHLJ/RSKP
Weakly supervised temporal action localization targets at localizing temporal boundaries of actions and simultaneously identify their categories with only video-level category labels. This paper proposes a representative snippet summarization and propagation framework. Our method seeks to mine the representative snippets in each video for better propagating information between video snippets. For each video, its own representative snippets and the representative snippets from a memory bank are propagated to update the input features in an intra- and inter-video manner. The pseudo labels are generated from the temporal class activation maps of the updated features to rectify the predictions of the main branch. Our method obtains superior performance in comparison to the existing methods on two benchmarks, THUMOS14 and ActivityNet1.3, achieving gains as high as 1.2% in terms of average mAP on THUMOS14.
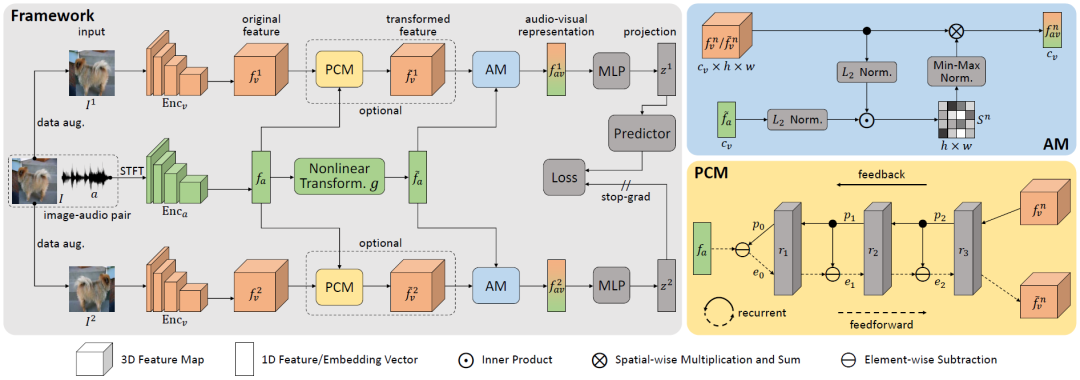
Self-Supervised Predictive Learning: A Negative-Free Method for Sound Source Localization in Visual Scenes
Authors: Zengjie Song, Yuxi Wang, Junsong Fan, Zhaoxiang Zhang, Tieniu Tan
Code: https://github.com/zjsong/SSPL
Sound source localization in visual scenes aims to localize objects emitting the sound in a given image. In this paper, we propose Self-Supervised Predictive Learning (SSPL), a negative-free method for sound localization via explicit positive mining. Specifically, we first devise a three-stream network to elegantly associate sound source with two augmented views of one corresponding video frame, leading to semantically coherent similarities between audio and visual features. Second, we introduce a novel predictive coding module for audio-visual feature alignment. Such a module assists SSPL to focus on target objects in a progressive manner and effectively lowers the positive-pair learning difficulty. Experiments show surprising results that SSPL outperforms the state-of-the-art approach on two standard sound localization benchmarks. In particular, SSPL achieves significant improvements of 8.6% cIoU and 3.4% AUC on SoundNet-Flickr compared to the previous best.
Artistic Style Discovery with Independent Components
Authors: Xin Xie, Yi Li, Huaibo Huang, Haiyan Fu, Wanwan Wang, Yanqing Guo
Style transfer has been well studied in recent years with excellent performance processed. While existing methods usually choose CNNs as the powerful tool to accomplish superb stylization, less attention was paid to the latent style space. Rare exploration of underlying dimensions results in the poor style controllability and the limited practical application. In this work, we rethink the internal meaning of style features, further proposing a novel unsupervised algorithm for style discovery and achieving personalized manipulation. In particular, we take a closer look into the mechanism of style transfer and obtain different artistic style components from the latent space consisting of different style features. Then fresh styles can be generated by linear combination according to various style components. Experimental results have shown that our approach is superb in 1) restylizing the original output with the diverse artistic styles discovered from the latent space while keeping the content unchanged, and 2) being generic and compatible for various style transfer methods.


Few-shot Backdoor Defense Using Shapley Estimation
Authors: Jiyang Guan, Zhuozhuo Tu, Ran He, Dacheng Tao
Prior works show that deep neural networks are easily manipulated into specific, attacker-decided behaviors in the inference stage by backdoor attacks which inject malicious small hidden triggers into model training, raising serious security threats. To determine the triggered neurons and protect against backdoor attacks, we exploit Shapley value and develop a new approach called Shapley Pruning (ShapPruning) that successfully mitigates backdoor attacks from models in a data-insufficient situation (1 image per class or even free of data). Considering the interaction between neurons, ShapPruning identifies the few infected neurons (under 1% of all neurons) and manages to protect the model's structure and accuracy after pruning as many infected neurons as possible. To accelerate ShapPruning, we further propose discarding threshold and epsilon-greedy strategy to accelerate Shapley estimation, making it possible to repair poisoned models with only several minutes. Experiments demonstrate the effectiveness and robustness of our method against various attacks and tasks compared to existing methods.

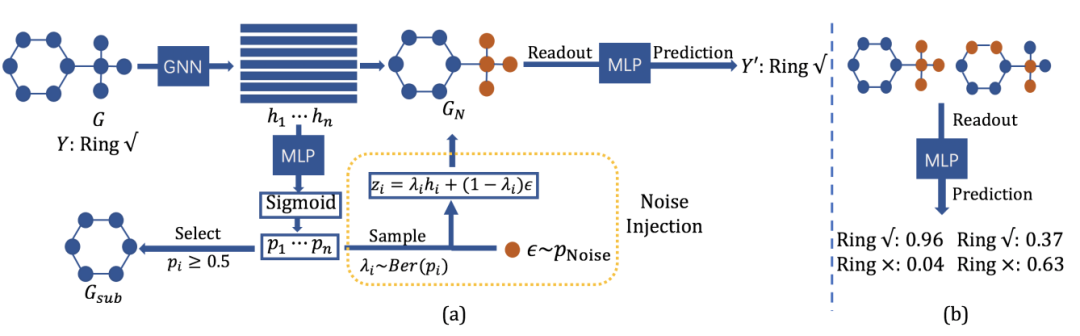
Improving Subgraph Recognition with Variational Graph Information Bottleneck
Authors: Junchi Yu, Jie Cao, Ran He
Subgraph recognition aims at discovering a compressed substructure of a graph that is most informative to the graph property. It can be formulated by optimizing Graph Information Bottleneck (GIB) with a mutual information estimator. However, GIB suffers from training instability and degenerated results due to its intrinsic optimization process. To tackle these issues, we reformulate the subgraph recognition problem into two steps: graph perturbation and subgraph selection, leading to a novel Variational Graph Information Bottleneck (VGIB) framework. VGIB first employs the noise injection to modulate the information flow from the input graph to the perturbed graph. Then, the perturbed graph is encouraged to be informative to the graph property. VGIB further obtains the desired subgraph by filtering out the noise in the perturbed graph. With the customized noise prior for each input, the VGIB objective is endowed with a tractable variational upper bound, leading to a superior empirical performance as well as theoretical properties. Extensive experiments on graph interpretation, explainability of Graph Neural Networks, and graph classification show that VGIB finds better subgraphs than existing methods.
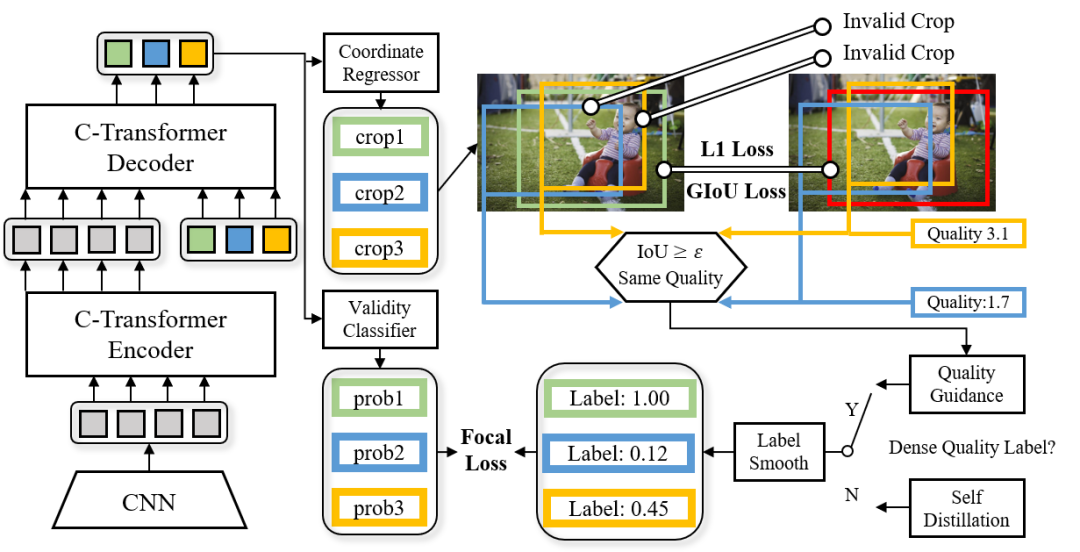
Rethinking Image Cropping: Exploring Diverse Compositions from Global Views
Authors: Gengyun Jia, Huaibo Huang, Chaoyou Fu, Ran He
Existing image cropping works mainly use anchor evaluation methods or coordinate regression methods. However, it is difficult for pre-defined anchors to cover good crops globally, and the regression methods ignore the cropping diversity. In this paper, we regard image cropping as a set prediction problem. A set of crops regressed from multiple learnable anchors is matched with the labeled good crops, and a classifier is trained using the matching results to select a valid subset from all the predictions. This new perspective equips our model with globality and diversity, mitigating the shortcomings but inherit the strengthens of previous methods. Despite the advantages, the set prediction method causes inconsistency between the validity labels and the crops. To deal with this problem, we propose to smooth the validity labels with two different methods. The first method that uses crop qualities as direct guidance is designed for the datasets with nearly dense quality labels. The second method based on the self distillation can be used in sparsely labeled datasets. Experimental results on the public datasets show the merits of our approach over state-of-the-art counterparts.
Learning the Degradation Distribution for Blind Image Super-Resolution
Authors: Zhengxiong Luo, Yan Huang, Shang Li, Liang Wang, Tieniu Tan
Code: https://github.com/greatlog/UnpairedSR
Synthetic high-resolution (HR) & low-resolution (LR) pairs are widely used in existing super-resolution (SR) methods. To avoid the domain gap between synthetic and test images, most previous methods try to adaptively learn the synthesizing (degrading) process via a deterministic model. However, some degradations in real scenarios are stochastic and cannot be determined by the content of the image. These deterministic models may fail to model the random factors and content-independent parts of degradations, which will limit the performance of the following SR models. In this paper, we propose a probabilistic degradation model (PDM), which studies the degradation D as a random variable, and learns its distribution by modeling the mapping from a priori random variable z to D. Compared with previous deterministic degradation models, PDM could model more diverse degradations and generate HR-LR pairs that may better cover the various degradations of test images, and thus prevent the SR model from over-fitting to specific ones. Extensive experiments have demonstrated that our degradation model can help the SR model achieve better performance on different datasets.

AnyFace: Free-style Text-to-Face Synthesis and Manipulation
Authors: Jianxin Sun, Qiyao Deng, Qi Li, Muyi Sun, Min Ren, Zhenan Sun
Existing text-to-image synthesis methods generally are only applicable to words in the training dataset. However, human faces are so variable to be described with limited words. So this paper proposes the first free-style text-to-face method namely AnyFace enabling much wider open world applications such as metaverse, social media, cosmetics, forensics, etc. AnyFace has a novel two-stream framework for face image synthesis and manipulation given arbitrary descriptions of the human face. Specifically, one stream performs text-to-face generation and the other conducts face image reconstruction. Facial text and image features are extracted using the CLIP (Contrastive Language-Image Pre-training) encoders. And a collaborative Cross Modal Distillation (CMD) module is designed to align the linguistic and visual features across these two streams. Furthermore, a Diverse Triplet Loss (DT loss) is developed to model fine-grained features and improve facial diversity. Extensive experiments on Multi-modal CelebA-HQ and CelebAText-HQ demonstrate significant advantages of AnyFace over state-of-the-art methods. AnyFace can achieve high-quality, high-resolution, and high-diversity face synthesis and manipulation results without any constraints on the number and content of input captions.

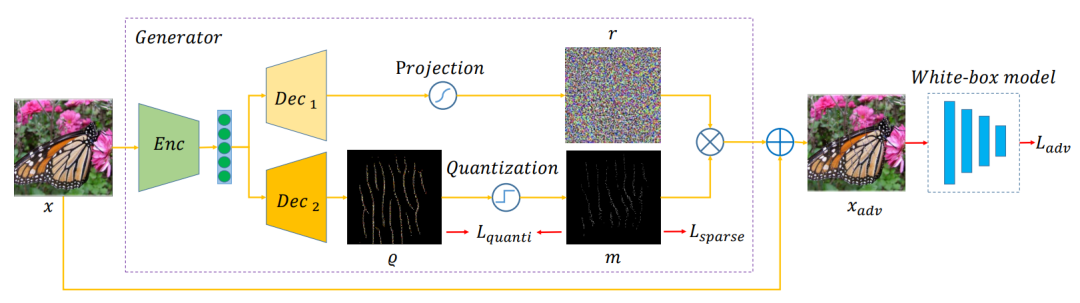
Transferable Sparse Adversarial Attack
Authors: Ziwen He, Wei Wang, Jing Dong, Tieniu Tan
Code: https://github.com/shaguopohuaizhe/TSAA
Deep neural networks have shown their vulnerability to adversarial attacks. In this paper, we focus on sparse adversarial attack based on the l_0 norm constraint, which can succeed by only modifying a few pixels of an image. Despite a high attack success rate, prior sparse attack methods achieve a low transferability under the black-box protocol due to overfitting the target model. Therefore, we introduce a generator architecture to alleviate the overfitting issue and thus efficiently craft transferable sparse adversarial examples. Specifically, the generator decouples the sparse perturbation into amplitude and position components. We carefully design a random quantization operator to optimize these two components jointly in an end-to-end way. The experiment shows that our method has improved the transferability by a large margin under a similar sparsity setting compared with state-of-the-art methods. Moreover, our method achieves superior inference speed, 700 times faster than other optimization-based methods.
Embracing Single Stride 3D Object Detector with Sparse Transformer
Authors: Lue Fan, Ziqi Pang, Tianyuan Zhang, Yu-Xiong Wang, Hang Zhao, Feng Wang, Naiyan Wang, Zhaoxiang Zhang
Code: https://github.com/wuhuikai/DeepGuidedFilter
In LiDAR-based 3D object detection for autonomous driving, the ratio of the object size to input scene size is significantly smaller compared to 2D detection cases. Overlooking this difference, many 3D detectors directly follow the common practice of 2D detectors, which downsample the feature maps even after quantizing the point clouds. In this paper, we start by rethinking how such multi-stride stereotype affects the LiDAR-based 3D object detectors. Our experiments point out that the downsampling operations bring few advantages, and lead to inevitable information loss. To remedy this issue, we propose Single-stride Sparse Transformer (SST) to maintain the original resolution from the beginning to the end of the network. Armed with transformers, our method addresses the problem of insufficient receptive field in single-stride architectures. It also cooperates well with the sparsity of point clouds and naturally avoids expensive computation. Eventually, our SST achieves state-of-the-art results on the large-scale Waymo Open Dataset. It is worth mentioning that our method can achieve exciting performance (83.8 LEVEL_1 AP on validation split) on small object (pedestrian) detection due to the characteristic of single stride.

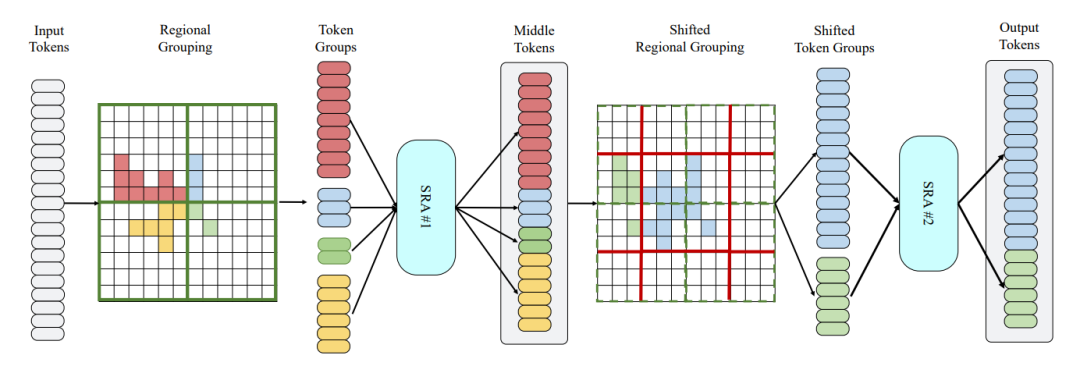
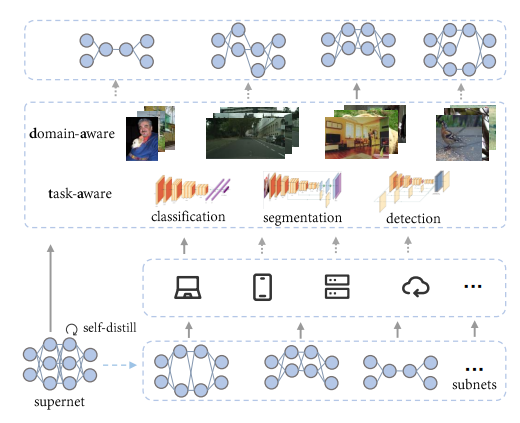
Domain-Aware and Task-Aware Self-Supervised Learning
Authors: Qing Chang, Junran Peng, Lingxi Xie, Jiajun Sun, Haoran Yin, Qi Tian, Zhaoxiang Zhang
Code: https://github.com/GAIA-vision/GAIA-ssl
The paradigm of training models on massive data without label through self-supervised learning (SSL) and finetuning on many downstream tasks has become a trend recently. However, due to the high training costs and the unconsciousness of downstream usages, most self-supervised learning methods lack the capability to correspond to the diversities of downstream scenarios, as there are various data domains, latency constraints and etc. Neural architecture search (NAS) is one universally acknowledged fashion to conquer the issues above, but applying NAS on SSL seems impossible as there is no label or metric provided for judging model selection. In this paper, we present DATA, a simple yet effective NAS approach specialized for SSL that provides Domain-Aware and Task-Aware pre-training. Specifically, we (i) train a supernet which could be deemed as a set of millions of networks covering a wide range of model scales without any label, (ii) propose a flexible searching mechanism compatible with SSL that enables finding networks of different computation costs, for various downstream vision tasks and data domains without explicit metric provided. Instantiated With MoCov2, our method achieves promising results across a wide range of computation costs on downstream tasks, including image classification, object detection and semantic segmentation. DATA is orthogonal to most existing SSL methods and endows them the ability of customization on downstream needs. Extensive experiments on other SSL methods, including BYOL, ReSSL and DenseCL demonstrate the generalizability of the proposed method.
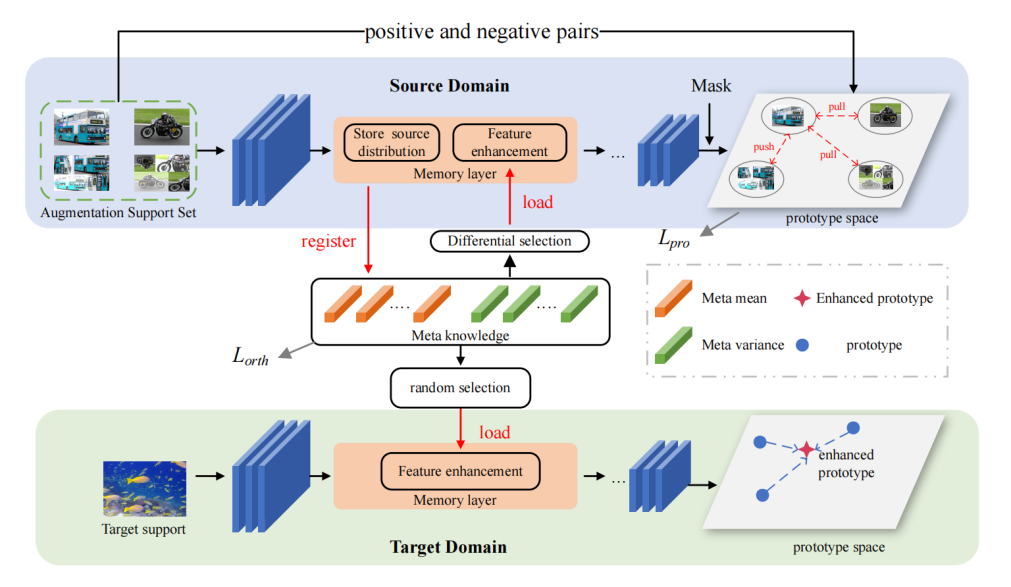
Remember the Difference: Cross-Domain Few-Shot Semantic Segmentation via Meta-Memory Transfer
Authors: Wenjian Wang, Lijuan Duan, Yuxi Wang, Qing En, Junsong Fan, Zhaoxiang Zhang
Few-shot semantic segmentation intends to predict pixel level categories using only a few labeled samples. Existing few-shot methods focus primarily on the categories sampled from the same distribution. Nevertheless, this assumption cannot always be ensured. The actual domain shift problem significantly reduces the performance of few-shot learning. To remedy this problem, we propose an interesting and challenging cross-domain few-shot semantic segmentation task, where the training and test tasks perform on different domains. Specifically, we first propose a meta-memory bank to improve the generalization of the segmentation network by bridging the domain gap between source and target domains. The meta-memory stores the intra-domain style information from source domain instances and transfers it to target samples. Subsequently, we adopt a new contrastive learning strategy to explore the knowledge of different categories during the training stage. The negative and positive pairs are obtained from the proposed memory-based style augmentation. Comprehensive experiments demonstrate that our proposed method achieves promising results on cross-domain few-shot semantic segmentation tasks on COCO-20, PASCAL-5, FSS-1000, and SUIM datasets.
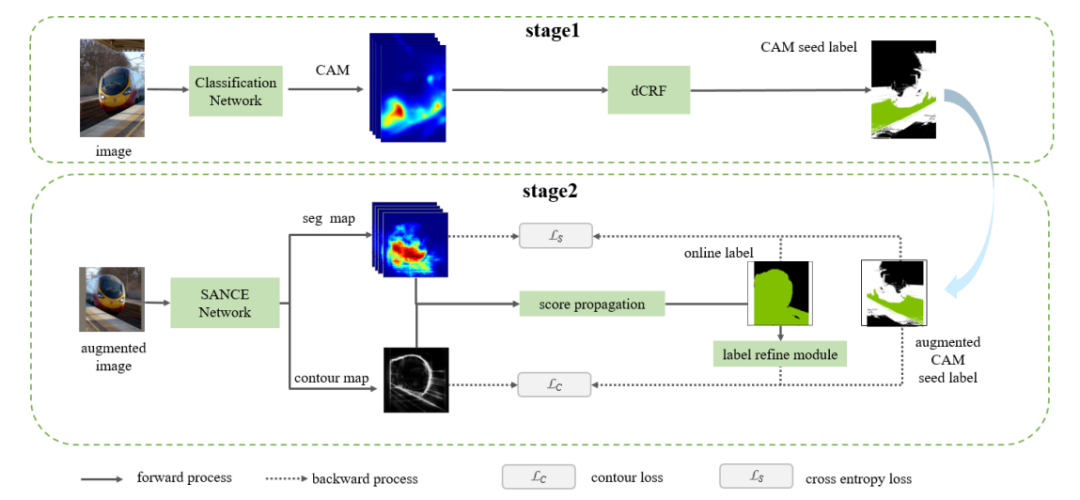
Towards Noiseless Object Contours for Weakly Supervised Semantic Segmentation
Authors: Jing Li, Junsong Fan, Zhaoxiang Zhang
Code: https: //github.com/BraveGroup/SANCE
Image-level label based weakly supervised semantic segmentation has attracted much attention since image labels are very easy to obtain. Existing methods usually generate pseudo labels from class activation map (CAM) and then train a segmentation model. CAM usually highlights partial objects and produce incomplete pseudo labels. Some methods explore object contour by training a contour model with CAM seed label supervision and then propagate CAM score from discriminative regions to non-discriminative regions with contour guidance. The propagation process suffers from the noisy intra-object contours, and inadequate propagation results produce incomplete pseudo labels. This is because the coarse CAM seed label lacks sufficient precise semantic information to suppress contour noise. In this paper, we train a SANCE model which utilizes an auxiliary segmentation module to supplement high-level semantic information for contour training by backbone feature sharing and online label supervision. The auxiliary segmentation module also provides more accurate localization map than CAM for pseudo label generation. We evaluate our approach on Pascal VOC 2012 and MS COCO 2014 benchmarks and achieve state-of-the-art performance, demonstrating the effectiveness of our method.
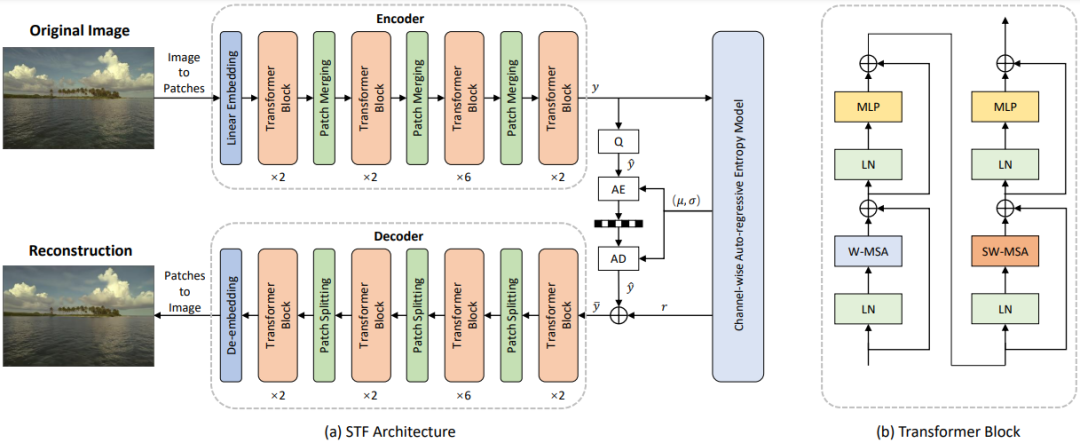
The Devil Is in the Details: Window-based Attention for Image Compression
Authors: Renjie Zou, Chunfeng Song, Zhaoxiang Zhang
Code: https://github.com/Googolxx/STF
Learned image compression methods have exhibited superior rate-distortion performance than classical image compression standards. Inspired by recent progresses of Vision Transformer (ViT) and Swin Transformer, we found that combining the local-aware attention mechanism with the global-related feature learning could meet the expectation in image compression. In this paper, we first extensively study the effects of multiple kinds of attention mechanisms for local features learning, then introduce a more straightforward yet effective window-based local attention block. The proposed window-based attention is very flexible which could work as a plug-and-play component to enhance CNN and Transformer models. Moreover, we propose a novel Symmetrical TransFormer (STF) framework with absolute transformer blocks in the down-sampling encoder and up-sampling decoder. Extensive experimental evaluations have shown that the proposed method is effective and outperforms the state-of-the-art methods.
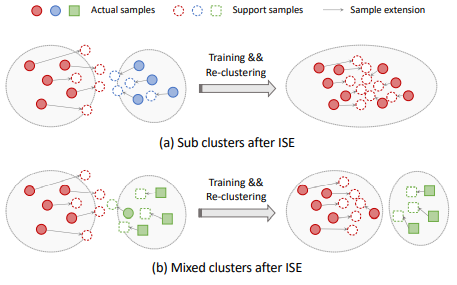
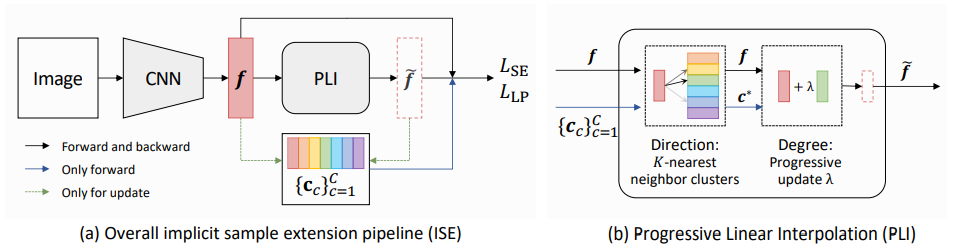
Implicit Sample Extension for Unsupervised Person Re-Identification
Authors: Xinyu Zhang, Dongdong Li, Zhigang Wang, Jian Wang, Errui Ding, Javen Qinfeng Shi, Zhaoxiang Zhang, Jingdong Wang
Code: https://github.com/PaddlePaddle/PaddleClas
Most existing unsupervised person re-identification (Re-ID) methods use clustering to generate pseudo labels for model training. We propose an Implicit Sample Extension (ISE) method to generate what we call support samples around the cluster boundaries. Specifically, we generate support samples from actual samples and their neighbouring clusters in the embedding space through a progressive linear interpolation (PLI) strategy. PLI controls the generation with two critical factors, i.e., 1) the direction from the actual sample towards its K-nearest clusters and 2) the degree for mixing up the context information from the K-nearest clusters. Meanwhile, given the support samples, ISE further uses a label-preserving loss to pull them towards their corresponding actual samples, so as to compact each cluster. Consequently, ISE reduces the "sub and mixed" clustering errors, thus improving the Re-ID performance. Extensive experiments demonstrate that the proposed method is effective and achieves state-of-the-art performance for unsupervised person Re-ID.
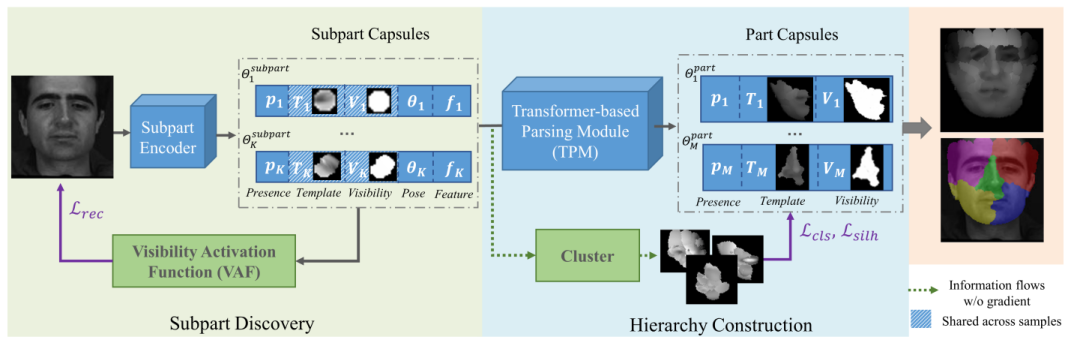
HP-Capsule: Unsupervised Face Part Discovery by Hierarchical Parsing Capsule Network
Authors: Chang Yu, Xiangyu Zhu, Xiaomei Zhang, Zidu Wang, Zhaoxiang Zhang, Zhen Lei
Code: https://github.com/PaddlePaddle/PaddleClas
In this paper, we propose a Hierarchical Parsing Capsule Network (HP-Capsule) for unsupervised face subpart-part discovery. When browsing large-scale face images without labels, the network first encodes the frequently observed patterns with a set of explainable subpart capsules. Then, the subpart capsules are assembled into part-level capsules through a Transformer-based Parsing Module (TPM) to learn the compositional relations between them. During training, as the face hierarchy is progressively built and refined, the part capsules adaptively encode the face parts with semantic consistency. HP-Capsule extends the application of capsule networks from digits to human faces and takes a step forward to show how the neural networks understand homologous objects without human intervention. Besides, HP-Capsule gives unsupervised face segmentation results by the covered regions of part capsules, enabling qualitative and quantitative evaluation. Experiments on BP4D and Multi-PIE datasets show the effectiveness of our method.

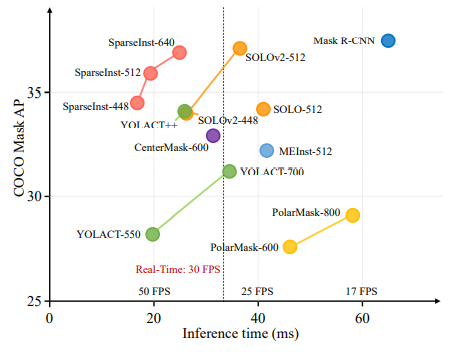
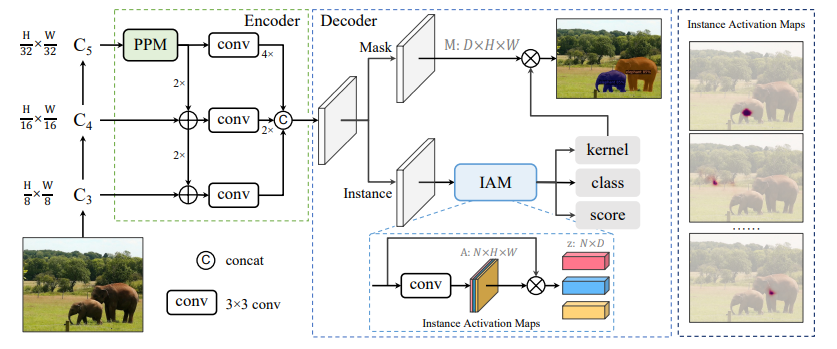
Sparse Instance Activation for Real-Time Instance Segmentation
Authors: Tianheng Cheng, Xinggang Wang, Shaoyu Chen, Wenqiang Zhang, Qian Zhang, Chang Huang, Zhaoxiang Zhang, Wenyu Liu
Code: https://github.com/hustvl/SparseInst
In this paper, we propose a conceptually novel, efficient, and fully convolutional framework for real-time instance segmentation. Previously, most instance segmentation methods heavily rely on object detection and perform mask prediction based on bounding boxes or dense centers. In contrast, we propose a sparse set of instance activation maps, as a new object representation, to highlight informative regions for each foreground object. Then instance-level features are obtained by aggregating features according to the highlighted regions for recognition and segmentation. Moreover, based on bipartite matching, the instance activation maps can predict objects in a one-to-one style, thus avoiding non-maximum suppression (NMS) in post-processing. Owing to the simple yet effective designs with instance activation maps, SparseInst has extremely fast inference speed and achieves 40 FPS and 37.9 AP on the COCO benchmark, which significantly outperforms the counterparts in terms of speed and accuracy.
Continual Stereo Matching of Continuous Driving Scenes with Growing Architecture
Authors: Chenghao Zhang, Kun Tian, Bin Fan, Gaofeng Meng, Zhaoxiang Zhang, Chunhong Pan
The deep stereo models have achieved state-of-the-art performance on driving scenes, but they suffer from severe performance degradation when tested on unseen scenes. Although recent work has narrowed this performance gap through continuous online adaptation, this setup requires continuous gradient updates at inference and can hardly deal with rapidly changing scenes. To address these challenges, we propose to perform continual stereo matching where a model is tasked to 1) continually learn new scenes, 2) overcome forgetting previously learned scenes, and 3) continuously predict disparities at deployment. We achieve this goal by introducing a Reusable Architecture Growth (RAG) framework. RAG leverages task-specific neural unit search and architecture growth for continual learning of new scenes. During growth, it can maintain high reusability by reusing previous neural units while achieving good performance. A module named Scene Router is further introduced to adaptively select the scene-specific architecture path at inference. Experimental results demonstrate that our method achieves compelling performance in various types of challenging driving scenes.

|