Facial editing has broad applications in movie effects and entertainments. Recent facial editing research flourishes with the success of GAN models [1]. However, previous methods either operate on pre-defined face attributes [2-3], lacking the flexibility of controlling shapes of facial components (e.g., eyes, nose, mouth), or take manually edited mask or sketch as an intermediate representation for observable changes [4-5], which requires extra efforts to obtain. To break the limitations (e.g. shape, mask or sketch) of the existing methods, our PhD student Qiyao Deng, Dr. Qi Li, and Prof. Zhenan Sun proposed a method named r-FACE (Reference guided FAce Component Editing) for diverse and controllable face component editing with geometric changes. The paper entitled “Reference Guided Face Component Editing” has been accepted by IJCAI 2020.
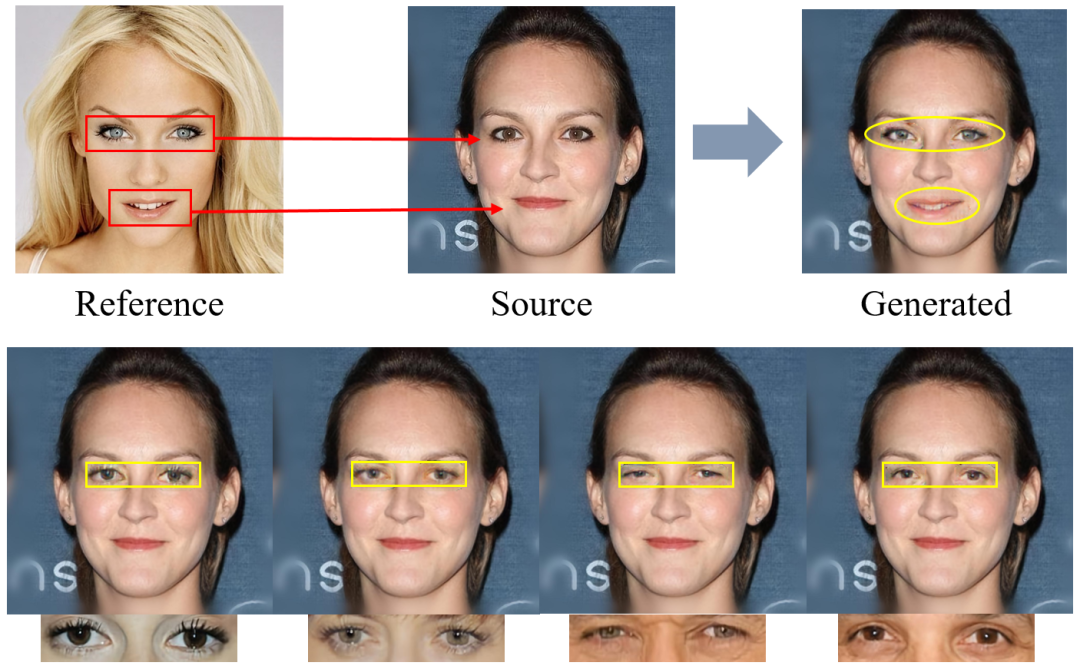
Fig.1 The illustration of reference-guided facial compositional editing.
The r-FACE model takes an image inpainting model as the backbone, utilizing reference images as conditions for controlling the shape of face components. To encourage the framework to concentrate on the target face components, an example-guided attention module is designed to fuse attention features and the target face component features extracted from the reference image. The method is detailed in Fig.2, on the top left corner is the generator, the top-right figure shows detailed attention module, and the constrains among the source image, the reference image and the generated image is shown on the bottom. Compared to the existing reference-based method [6], which requires the reference images to be from the same identity, the proposed method can use unconstrained identities as references to generate more diverse results.
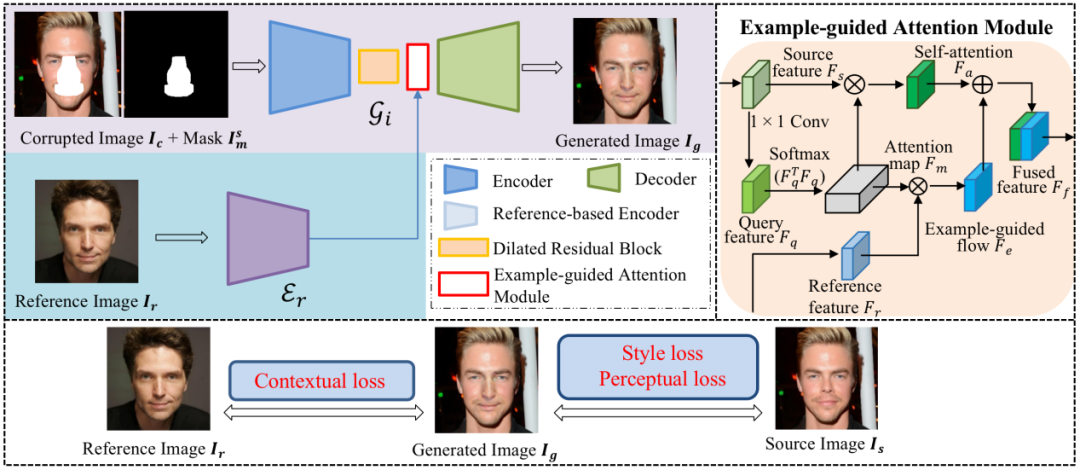
Fig.2 The overall structure of the rFACE model.
Experiments were conducted on the commonly used facial attributes dataset - CelebA-HQ. The results show that rFACE can generate both quality and diverse facial editing effects, and it can composite a new face appearance using facial components from other very different face images.

Fig.3 Comparisons between the results of different methods. (a) and (b) are input and reference images, respectively. (c) is direct copy, (d) is AttGAN, (e) is ELEGANT, (f) is Adobe Photoshop, and (g) is the proposed r-FACE.

Fig.4 Sample results of mixed facial composition
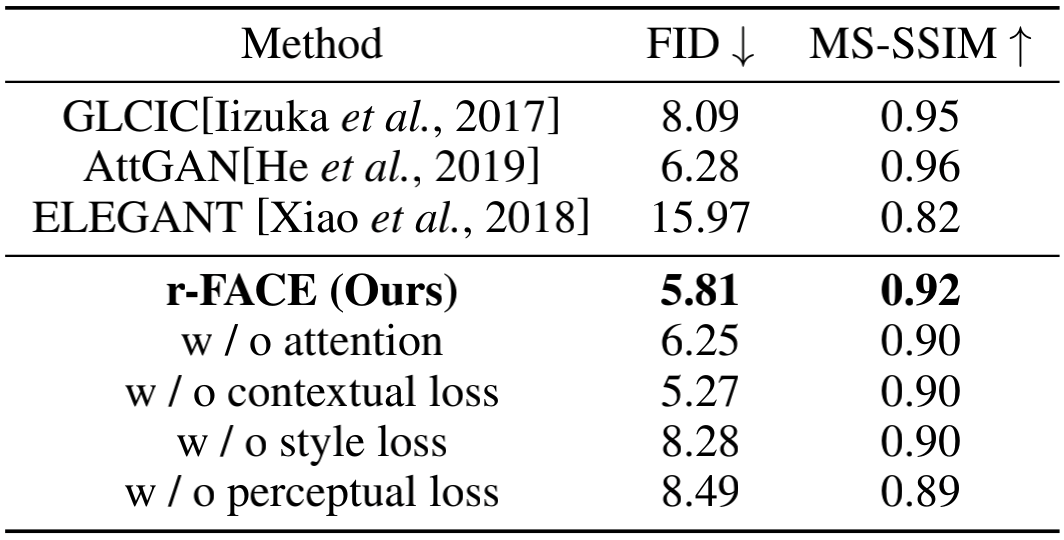
Table 1 Quantitative comparision on the CelebA-HQ dataset
Reference papers:
[1] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, pages 2672–2680, 2014.
[2] Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In CVPR, pages 8789–8797, 2018.
[3] Zhenliang He, Wangmeng Zuo, Meina Kan, Shiguang Shan, and Xilin Chen. AttGAN: Facial attribute editing by only changing what you want. IEEE TIP, 2019.
[4] Shuyang Gu, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen, and Lu Yuan. Maskguided portrait editing with conditional GANs. In CVPR, pages 3436–3445, 2019.
[5] Youngjoo Jo and Jongyoul Park. SC-FEGAN: Face editing generative adversarial network with user’s sketch and color. In ICCV, October 2019.
[6] Brian Dolhansky and Cristian Canton Ferrer. Eye in-painting with exemplar generative adversarial networks. In CVPR, pages 7902–7911, 2018.
|