今天给大家分享一篇我中心刚刚被TPAMI接收的论文:Constructing Stronger and Faster Baselines for Skeleton-based Action Recognition。这篇论文将复合缩放策略(compound scaling strategy)应用到骨架行为识别中,提出了EfficientGCN模型,以接近1/6的参数量和推理速度,实现了与SOTA模型相近的top-1识别正确率。希望能够给大家带来一些深度学习模型结构构建上的思考。
论文地址:
https://ieeexplore.ieee.org/document/9729609
开源代码:
https://gitee.com/yfsong0709/EfficientGCNv1
1. 问题提出
行为识别是计算机视觉领域中的一个经典问题,其要求对一段视频进行分析,从而识别出视频中的运动目标正在进行的动作类别。传统的行为识别方法主要分为两类,分别是基于卷积网络的C3D、I3D等模型和基于循环网络的LRCN等模型。然而,由于传统方法都是基于RGB视频进行分析建模,大量的数据会导致模型参数量大、收敛困难。同时,传统模型还存在这严重的信息冗余,视频中的背景、光照条件都会严重影响到模型的鲁棒性。
近年来,随着姿态估计算法的不断进步,基于骨架的行为识别逐渐走进研究人员的视野。特别是在2018年之后,GCN算法被引入骨架行为识别中,极大地推动了领域的发展。由于人体骨架是一个天然的图结构,GCN算法能够非常自然地对人体骨架图进行建模,从而避免了空间结构信息的损失。基于此,骨架行为识别逐渐成为了一个热门研究方向。我们将会介绍一下如何从零开始搭建出骨架行为识别的深度学习模型。
2. 基础模块
数据预处理模块
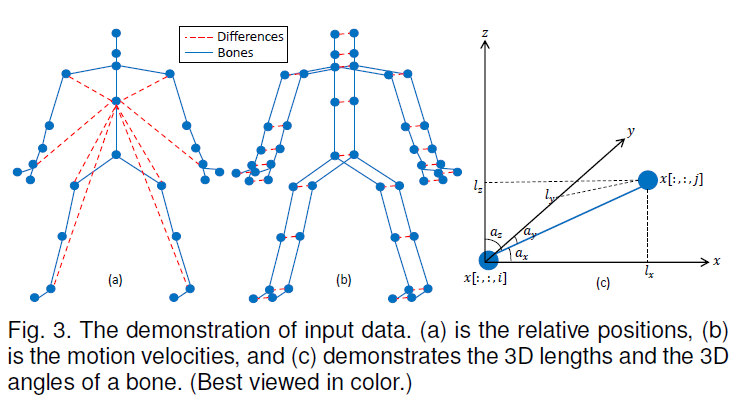
假设我们已经得到了一个三维骨架绝对坐标序列X={x∈R^(C_in×T_in×V_in )},其中C_in=3、T_in、V_in分别是骨架序列的维数、帧数以及一帧内的骨架点数。据此,我们就可以计算出该骨架序列的相对坐标序列r_i=x[:,:,i]-x[:,:,c],其中c代表了中心骨架点的序号(通常是脊柱中点)。对于时间维度,我们也可以基于绝对坐标序列X计算出间隔帧间差f_t=x[:,t+2,:]-x[:,t,:]和相邻帧间差s_t=x[:,t+1,:]-x[:,t,:]。同样的,在骨架信息上,我们也可以计算出每个骨架的长度l_i=x[:,:,i]-x[:,:,i_adj],其中i_adj表示与骨架点i相连接的骨架点,并根据骨架长度计算出骨架三维旋转角。
空间GCN模块(SGC)
Yan等人[1]首次提出了基于GCN的骨架行为识别算法ST-GCN,其每一层可归结为如下公式:

其中,v_ti代表了序列中第t帧第i个骨架点,f_in和f_out分别表示输入和输出特征,N(v_ti)表示v_ti的邻居集合,Z_ti则是用来平衡不同邻居的标准项,w()表示加权函数,l_ti ()表示分类函数。Yan等人[1]提出了三种分类函数,我们仅选用了其中的距离分类函数,即l_ti (v_tj )=d(v_ti,v_tj),其中d(v_ti,v_tj)代表了任意两点之间的图上距离,相邻骨架点的距离为1,邻居的邻居距离为2,以此类推。采用预先定义好的人体骨架图临界矩阵A对上式进行转换,可得到矩阵形式的GCN公式:
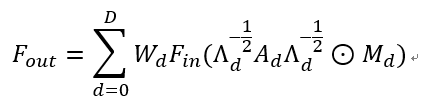
其中,D是一个超参数,表示最大距离,A_d表示距离为d的邻接矩阵,Λ_d用来对A_d进行标准化,W_d和M_d则是可训练参数。上述ST-GCN层在本文中用于空间信息的建模。
时序CNN模块(TC)
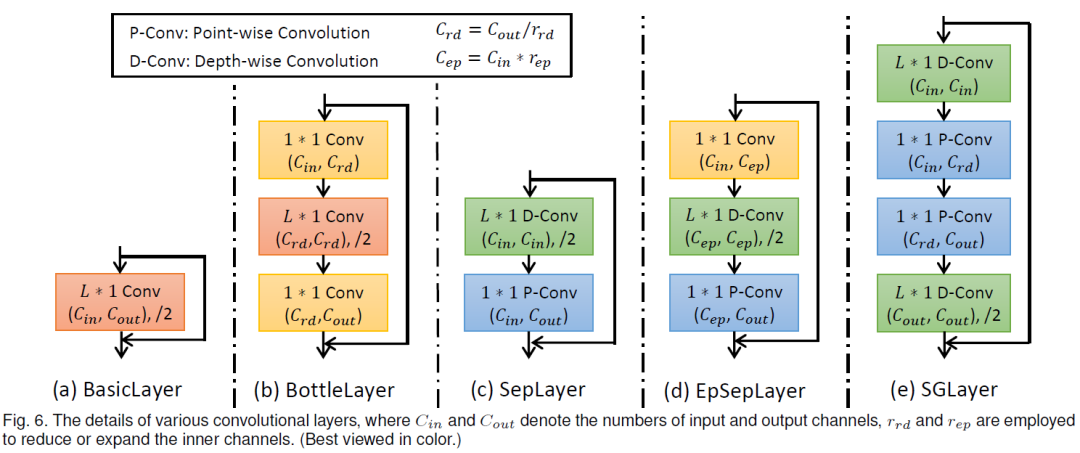
除了空间GCN模块外,在骨架序列的不同帧之间,还需要相互传递信息来实现运动信息的建模。我们采用了一维的CNN层来实现时序信息建模,就是认为每个骨架点的时序信息仅与前后相邻的几帧中的同骨架点相关,该一维CNN层的卷积核长度是一个超参数L。此外,为了降低模型的参数量,我们还可以引入bottleneck结构或可分离卷积结构,构造出如下五种时序CNN层:
Attention模块
在人体运动过程中,我们很自然地就会想到人体的每一个骨架点在每个时刻的重要性是在不断变化的。但是,早起的骨架行为识别模型采用的attention模块基本都是单独给每一帧或者每一个骨架点分配不同的注意力权重。为了更加符合实际中的运动情况,我们提出了一种时空骨架点attention,通过每一帧上的每个骨架点进行不同的权重分配,来实现更加灵活的模型学习。然而,若是采用类似于SENet或self-attention之类的模块来计算注意力的话,会导致运算量的急剧上升,因为一个骨架序列中的时空骨架点数量一共有T*V个(大约300*25个),这显然已经超出了GPU的承受范围。所以,我们采用SENet结构,将骨架序列的空间和时序分开进行,分别计算出C*T的时序注意力矩阵和C*V的空间注意力矩阵,然后对两注意力矩阵进行矩阵乘法进行合并,即可得到一个C*T*V的时空注意力矩阵。整个模块的流程如下图所示:
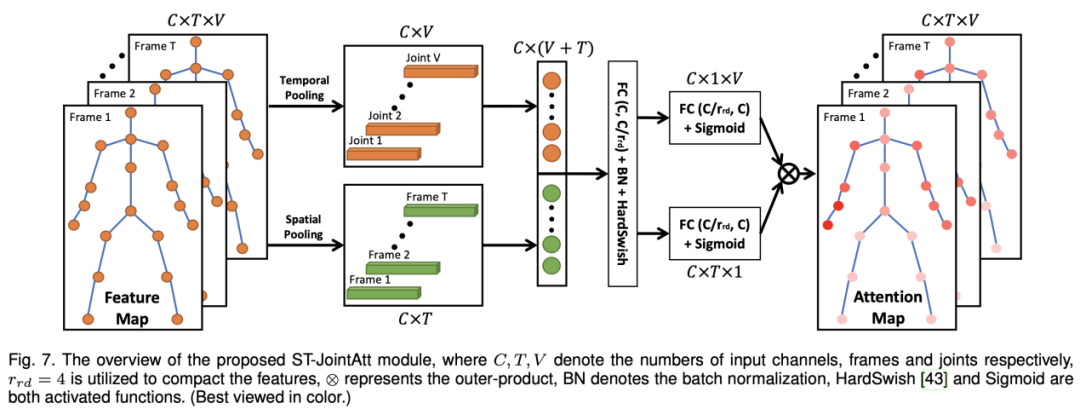
3. 模型构建
模型框架
有了第2章中所描述的四个模块后,我们就可以开始搭建骨架行为识别模型了。首先,在得到一个骨架序列后,我们先用数据预处理模块进行处理,分别获取到Joint输入(三维绝对坐标、三维相对坐标),Velocity输入(间隔帧间差、相邻帧间差),Bone输入(三维骨架长度、三维骨架旋转角),然后分别送到三个input branch里。将三个input branch的输出进行汇总后,再送入一个main stream里,最后的输出经过全局均值池化后,利用一个FC层来实现行为分类。上面提到的input branch和main stream均是两个GCN block堆叠而成,而每个GCN block则包含了一个GCN层,一个attention层,以及多个TC层组成。多个TC层是为了让模型能够更好的掌握相聚较远的两帧之间的关系,比起一个超大的卷积核,多层小卷积核的堆叠效果更加理想。SGC层只选取一个是因为整个人体骨架一共只有25个点,不存在空间距离特别长的骨架点对。整个模型框架的示意图如下所示:
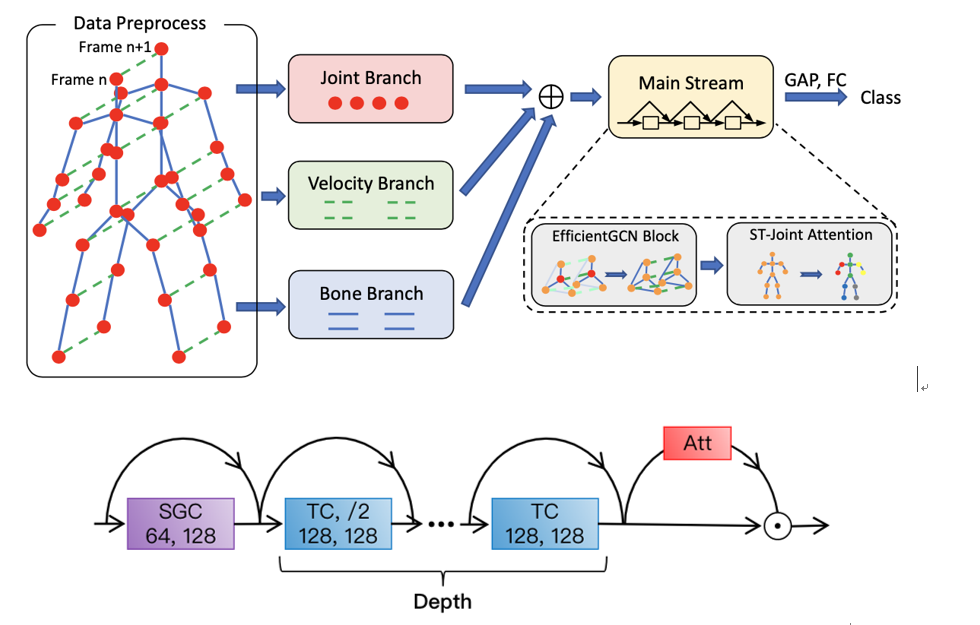
缩放策略
有了每一个模块的细节以及整个模型的框架后,我们现在需要做的仅剩下选择合适的超参数了。除了上述的两个超参数外(最大图距离D、时序卷积核长度L),每个GCN block的输入输出channel(width)、TC数量(depth)同样也是关键。同样的,直觉上我们认为,每个block的width和depth应该是同步增加更为有效。因此,我们设计了一种复合缩放策略如下:
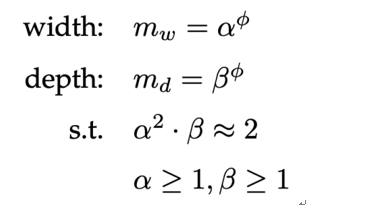
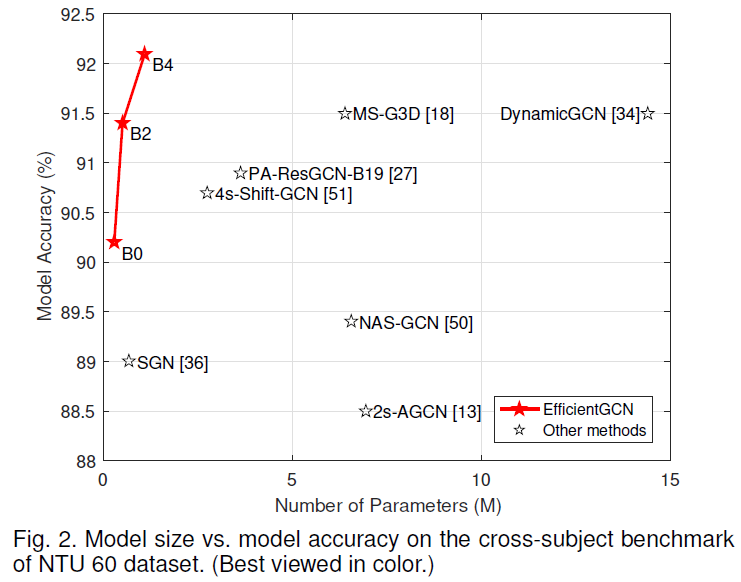
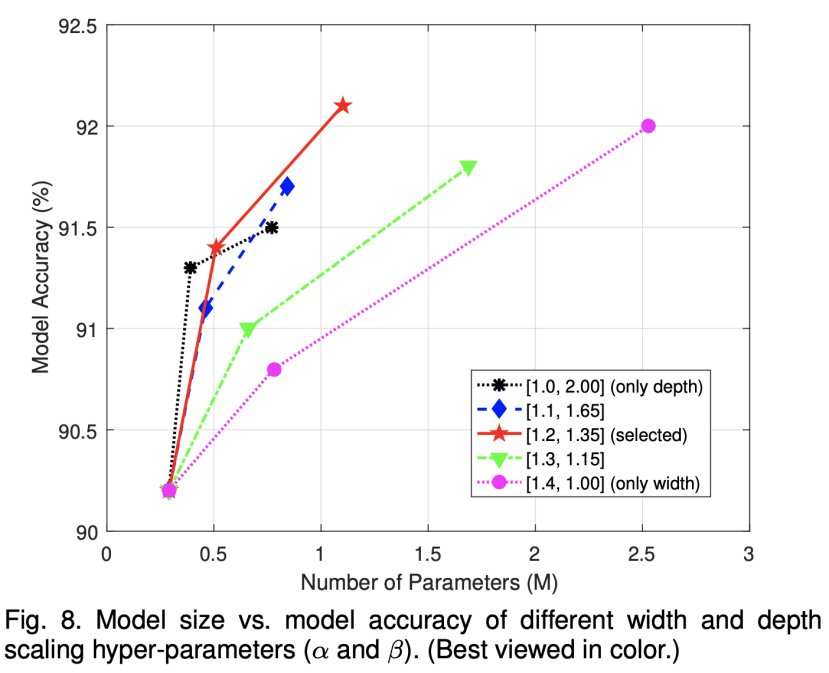
上式中,α、β和?是三个超参数,用来确定模型的大小。其中,α越大,模型对width的提升越明显;β越大,模型对depth的提升越明显;而?则是用来控制模型的参数量大小。至此,整个骨架行为识别模型就已经构建完成了。由于其高效性,我们给它取名为EfficientGCN-Bx,其中x就是?的大小。对于α、β的选取,下图可以作为参考。最终我们选定α=1.2,β=1.35,?={0,2,4}作为三种不同参数量和识别精度的模型,用于不同的场景中。
4. 实验结果
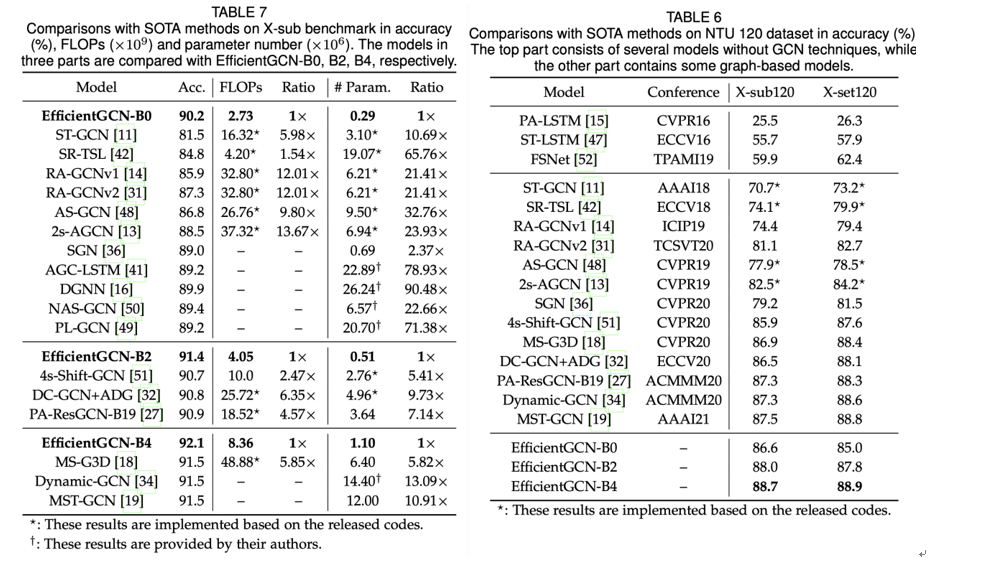
本文的实验主要在NTU-60和NTU-120两个数据库上进行的。从左边的表格可以看出,我们的模型在相似top-1正确率的情况下,可以实现数倍的参数量缩减。与当前的SOTA模型MS-G3D对比,EfficientGCN-B4模型在参数量、运行速度上均接近MS-G3D的1/6,而正确率还要高了0.6%。由此可以看出我们模型的高效性。同样的,在NTU-120数据库上,EfficientGCN-B4也取得了超越SOTA模型的效果。
5. 结语
本文讲述了一个完整的构建骨架行为识别深度模型的过程,所发表的TPAMI论文已可Early Access,论文所用代码也传到了Gitee上。更加详细的内容欢迎大家下载查阅。
|